前言:我们都还在黑暗中摸索
坦白说,过去三个月我一直在AI Agent的开发世界里打转。
有时候觉得自己做出了点东西——技能能跑了,能生成图片了,能翻译文档了。但过两天又发现代码写得一团糟,SKILL.md里塞满了各种应急补丁,改一处bug就要动三处不相关的代码。
我一直在问自己:到底怎么写一个能扛得住真实场景的Agent技能?
直到昨天,在X上GoogleCloudTech发表的一篇名为《5 Agent Skill design patterns every ADK developer should know》。那一刻就像是在漆黑的隧道里突然看到了光——原来我踩过的那些坑,早就有成熟的模式可以规避; 原来我在 beaver-skill 项目里摸索出来的那点实践,居然 真的对应着某种”最佳实践”。
看完理论再回头看自己写的代码,那种”原来当时我这么做是对的”的确认感,以及”早知道这个概念,当时可以写得更好”的遗憾,真的很想分享出来。
如果你也在Agent开发的路上摸索,希望这篇文能帮你理清一些思路。我们都是在AI新时代里一起探索的同行者。
先来一张全景图
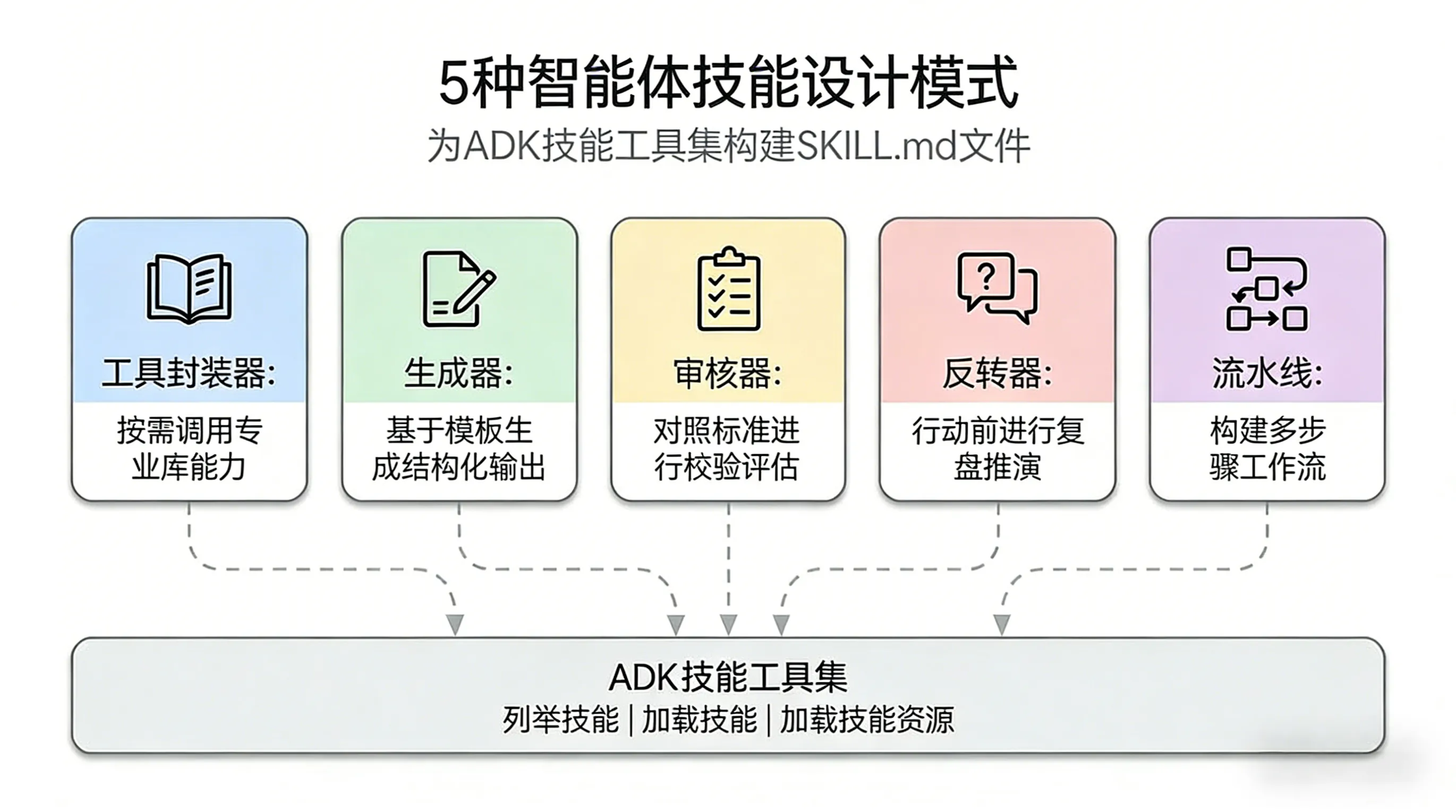
这五种模式,我在 beaver-skill 项目里其实都用过——只是那时候不知道这就是”模式”,只是觉得”这样好像更合理”。看完理论后再对照自己的代码,才真正理解了每种模式的精髓。
| 设计模式 | 我当时的问题 | 理论说的是什么 | 我在beaver-skill里怎么做的 |
|---|---|---|---|
| Tool Wrapper | API文档全塞进SKILL.md,文件越来越长 | 把库文档外部化,按需加载 | beaver-image-gen 的多平台抽象 |
| Generator | 每次生成的风格都不稳定 | 用模板+风格指南强制统一输出 | beaver-cover-image 的9×6风格矩阵 |
| Reviewer | 从来没写过审查技能 | 把检查标准外部化,可替换 | 可以扩展的模式 |
| Inversion | 老是猜用户需求 | 让agent当面试官,先问清楚再动手 | beaver-xhs-images 的双重确认流程 |
| Pipeline | 一次性做完所有事,出错就要重来 | 多个检查点,每步都要确认 | beaver-markdown-i18n 的翻译流水线 |
接下来,我想聊聊每个模式——从我当时踩过的坑说起,到看到理论时的顿悟,再到回头看自己代码时的反思。
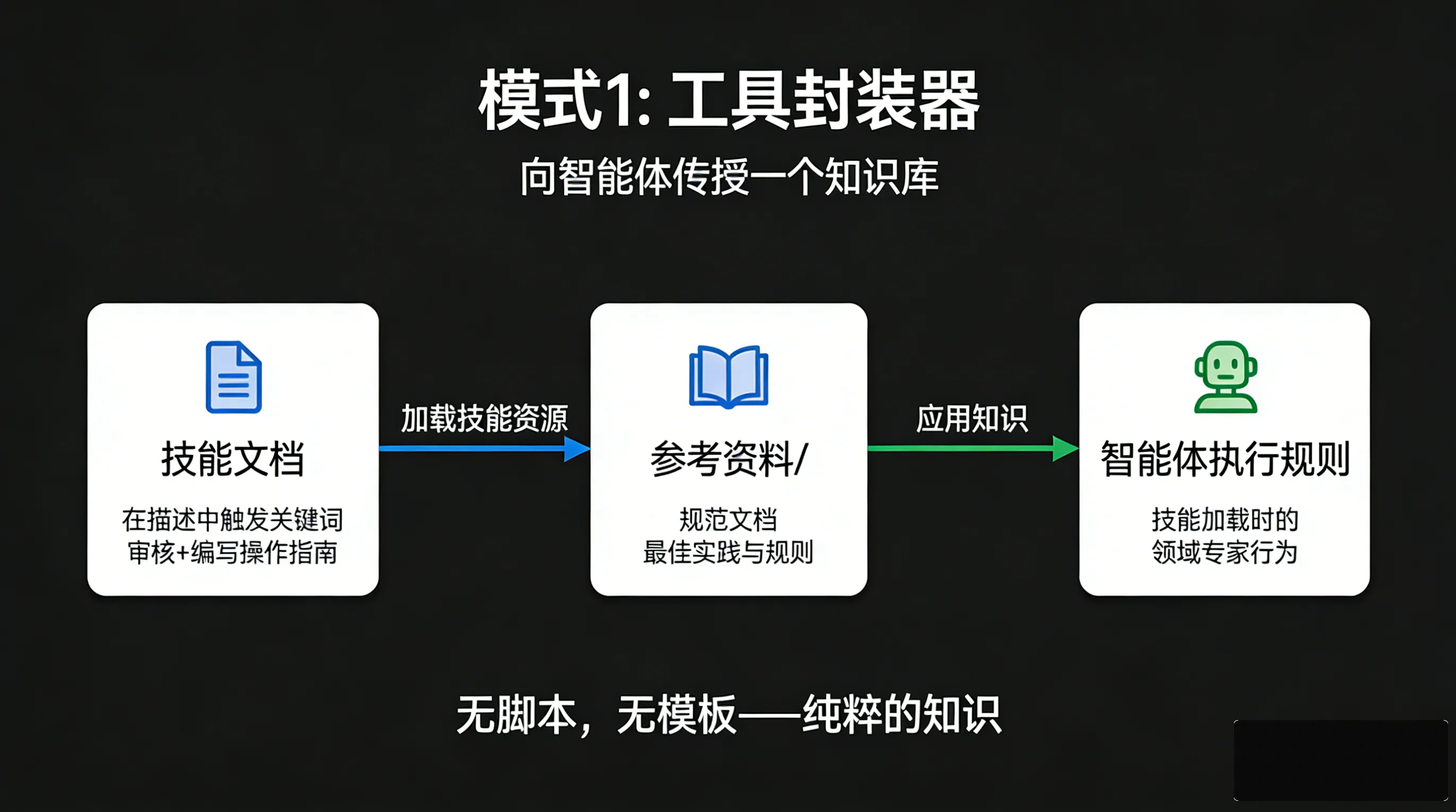
模式1:Tool Wrapper——原来API文档可以不用塞进SKILL.md
我踩过的坑
最开始写 beaver-image-gen 的时候,我把Nano、OpenAI的API文档直接写进了SKILL.md。结果就是:
- 文件越来越长,翻到真正的逻辑要划半天
- 想支持新平台,要在SKILL.md里加一大段说明
- 不同平台的规则混在一起,经常用错
那时候我就想:能不能把平台相关的文档单独拎出来?
于是我搞了个 scripts/providers/ 目录,把每个平台的约定拆成独立文件。当时只是觉得”这样更清爽”,不 知道这就是Tool Wrapper模式。
理论说的是什么
Tool Wrapper 模式的核心就一句话:让agent成为特定库的即时专家,但别把库文档写死在代码里。
关键点:
- 外部化知识库——库文档单独维护
- 动态加载——需要哪个库就加载哪个
- 按需上下文——别一次性把所有文档塞给agent
我在beaver-skill里的实现
beaver-image-gen/├── scripts/providers/│ ├── google.ts│ ├── openai.ts│ ├── dashscope.ts│ └── replicate.ts├── main.ts└── SKILL.md每个平台的API约定都是独立的TypeScript模块。现在回头看,当时的直觉是对的。
对照理论,看看我当时做对了什么:
| 理论要素 | 我的实现 | 对应代码位置 |
|---|---|---|
| 外部化知识库 | 每个平台独立文件 | scripts/providers/*.ts |
| 动态加载 | detectProvider() 自动选择 | main.ts |
| 按需上下文 | SKILL.md 里用 If Google... 条件指令 | SKILL.md |
回头看可以做得更好的地方
虽然方向对了,但现在看完理论,有些地方可以优化:
| 当时的做法 | 现在的想法 |
|---|---|
| 平台检测后直接返回provider | 可以加个fallback机制,检测失败时更友好 |
| 条件指令写在SKILL.md里 | 可以考虑把prompt模板也抽到providers里 |
| 没有provider的元数据描述 | 可以加个版本号、支持特性等描述,便于扩展 |
这些改进点,我在下一版迭代里会加上。
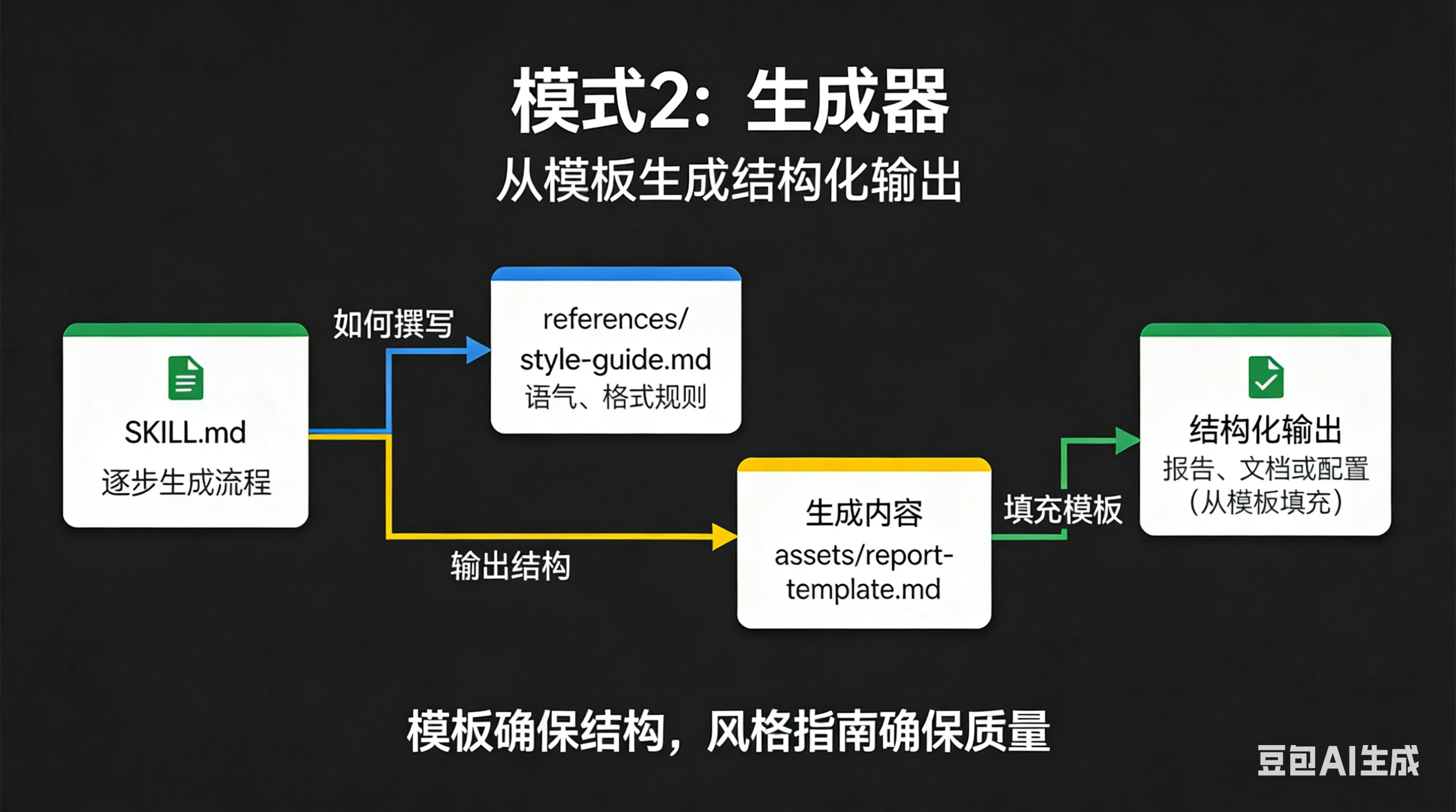
模式2:Generator——别再让AI自由发挥了
我踩过的坑
写 beaver-cover-image 之前,我试过直接让AI生成封面。结果很痛苦:每次风格都不一样,配色经常翻车, 没有统一的视觉语言。
我就想:能不能有个”风格配方”,每次都按配方来?
理论说的是什么
Generator 模式的核心是:用模板+风格指南,强制输出格式一致。
关键点:
- 模板存储——输出模板放在
assets/ - 风格指南——格式规则放在
references/ - 填空过程——agent只负责填变量,不是自由创作
beaver-skill里的实现
beaver-cover-image/├── assets/ # 模板│ ├── template-cinematic.md│ └── template-square.md├── references/ # 风格指南│ ├── palettes/ # 9种色板│ └── styles/ # 6种渲染风格对照理论,我当时的思路:
| 理论要素 | beaver-skill的实现 | 对应位置 |
|---|---|---|
| 模板存储 | 不同aspect ratio的模板 | assets/template-*.md |
| 风格指南 | 9种色板 × 6种渲染风格 | references/palettes/ + references/styles/ |
| 填空过程 | 按顺序收集:标题→副标题→视觉元素→风格 | SKILL.md 的生成流程 |
回头看可以做得更好的地方
| 当时的做法 | 现在的想法 |
|---|---|
| 风格配置是yml文件 | 可以考虑加个可视化选择器 |
| 没有记录用户的历史偏好 | 可以集成EXTEND.md,记住用户常用的风格 |
| 风格组合是固定的54种 | 可以允许”半定制”——固定色板,微调风格参数 |
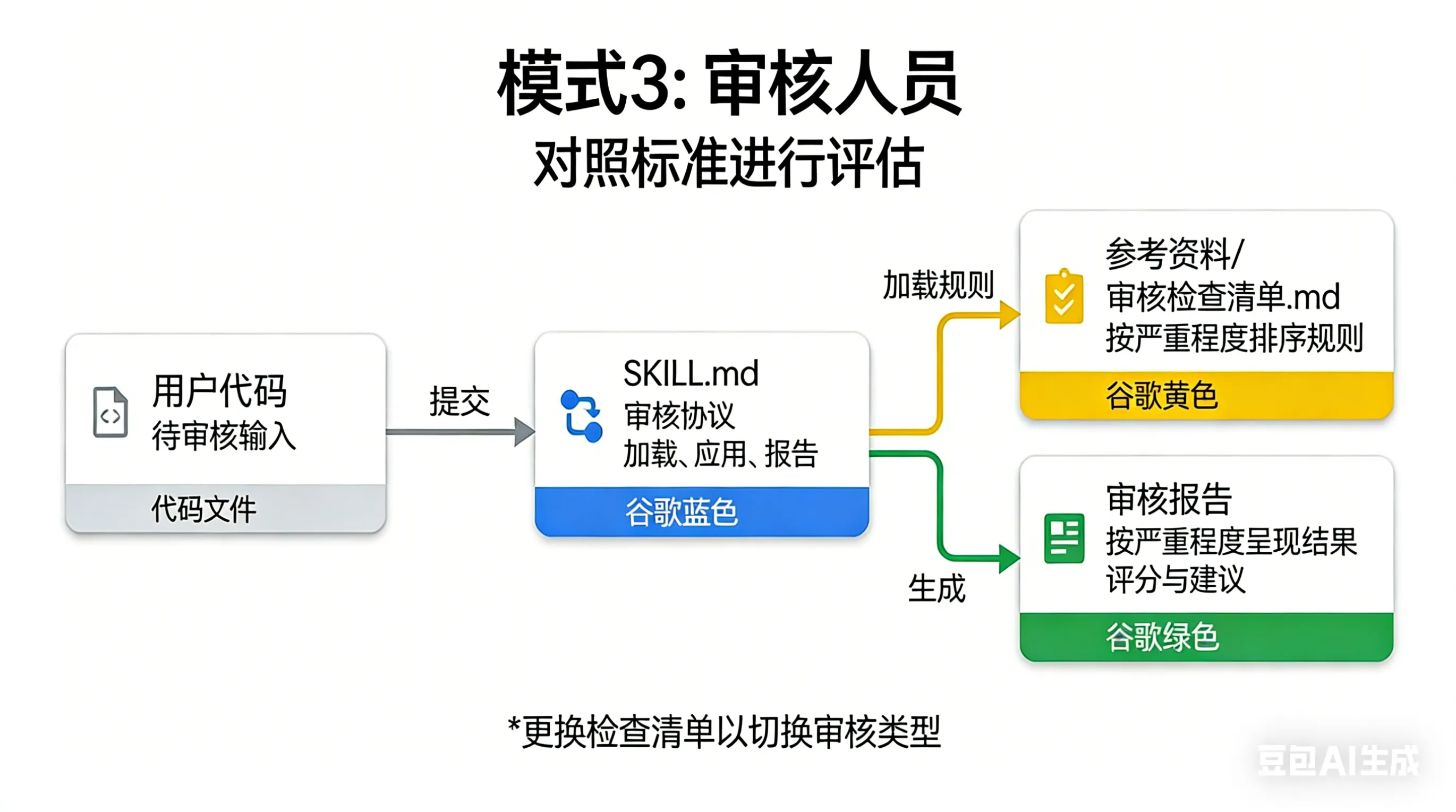
模式3:Reviewer——还没做,但已经知道怎么做了
我的现状
说实话,Reviewer模式我还没在 beaver-skill 里落地。每次代码review还是人工看,或者让AI直接扫一遍, 没有固定的检查清单。
看了理论之后,我意识到这个问题:审查标准都在脑子里,每次都不一样,也不容易传承。
理论说的是什么
Reviewer 模式很简单:把检查清单外部化,按严重性分组,可以灵活替换。
关键点:
- 标准外部化——审查规则独立文件
- 严重性分组——error/warning/info三级
- 可替换清单——同一框架可切换不同标准
如果我要加一个Reviewer技能
现在我知道该怎么设计了:
code-reviewer/├── references/│ ├── checklists/│ │ ├── typescript-style.md│ │ ├── owasp-security.md│ │ └── performance.md│ └── severity-guide.md└── SKILL.md核心流程:
- 根据参数加载对应的checklist
- 逐条检查代码
- 按严重性分组输出:error(必须修)/warning(建议修)/info(提示)
这个技能已经在我TODO列表上了。
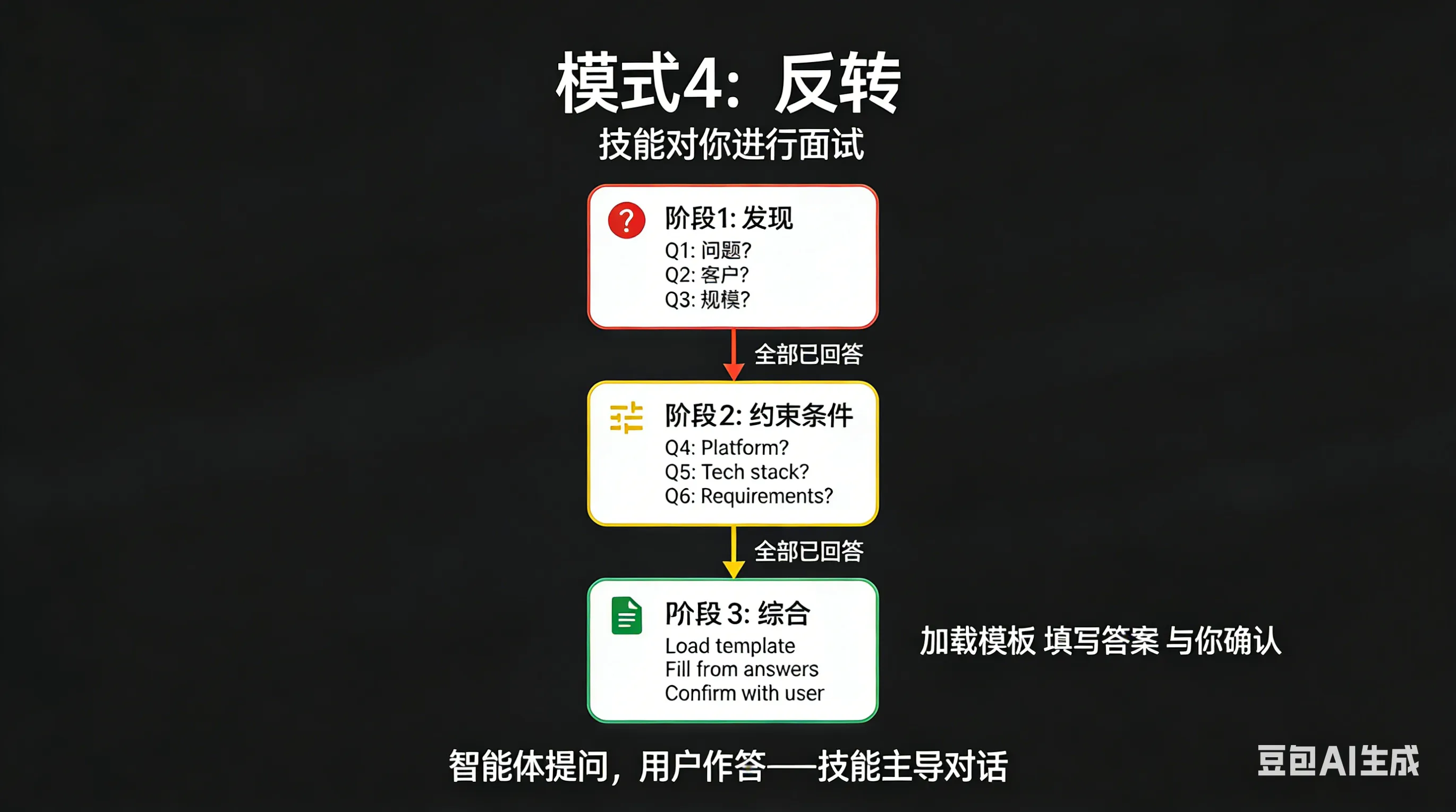
模式4:Inversion——别猜了,直接问吧
我踩过的坑
做 beaver-xhs-images 的时候,我一开始总想着”智能推断”用户想要什么风格。结果呢?经常推断错,生成一堆不对胃口的内容。
后来我干脆不猜了,直接问——效果反而好了很多。
理论说的是什么
Inversion 模式颠覆了传统思路:agent不是执行者,是面试官。
关键点:
- 门控指令——⛔必须完成才能继续
- 分阶段收集——需求分多次确认
- 完整图景——确保信息完整再动手
beaver-skill中的实现
Step 0: 偏好检查 ⛔ BLOCKING ├─ 检查 EXTEND.md └─ 不存在就强制首次设置
Step 2: 确认内容理解 ⚠️ REQUIRED ├─ 展示提取的主题 └─ 等用户确认
Step 4: 确认风格 ⚠️ REQUIRED ├─ 展示选择的大纲和风格 └─ 等用户确认两个确认点,这比我一开始直接生成要靠谱多了。
对照理论,看看我当时的设计:
| 理论要素 | beaver-skill中的实现 | 对应位置 |
|---|---|---|
| 门控指令 | ⛔ BLOCKING,首次设置必须完成 | Step 0 |
| 分阶段收集 | Step 2/4 的AskUserQuestion | SKILL.md |
| 完整图景 | 两个⚠️ REQUIRED检查点 | SKILL.md |
回头看可以做得更好的地方
| 当时的做法 | 现在的想法 |
|---|---|
| EXTEND.md只存了风格偏好 | 可以加个”最近生成历史”,方便复用 |
| 确认点是在Step 2和4 | 可以考虑让用户自定义确认点的位置 |
| 偏好检查是强制性的 | 可以加个”跳过首次设置”的选项,但提示可能效果不佳 |
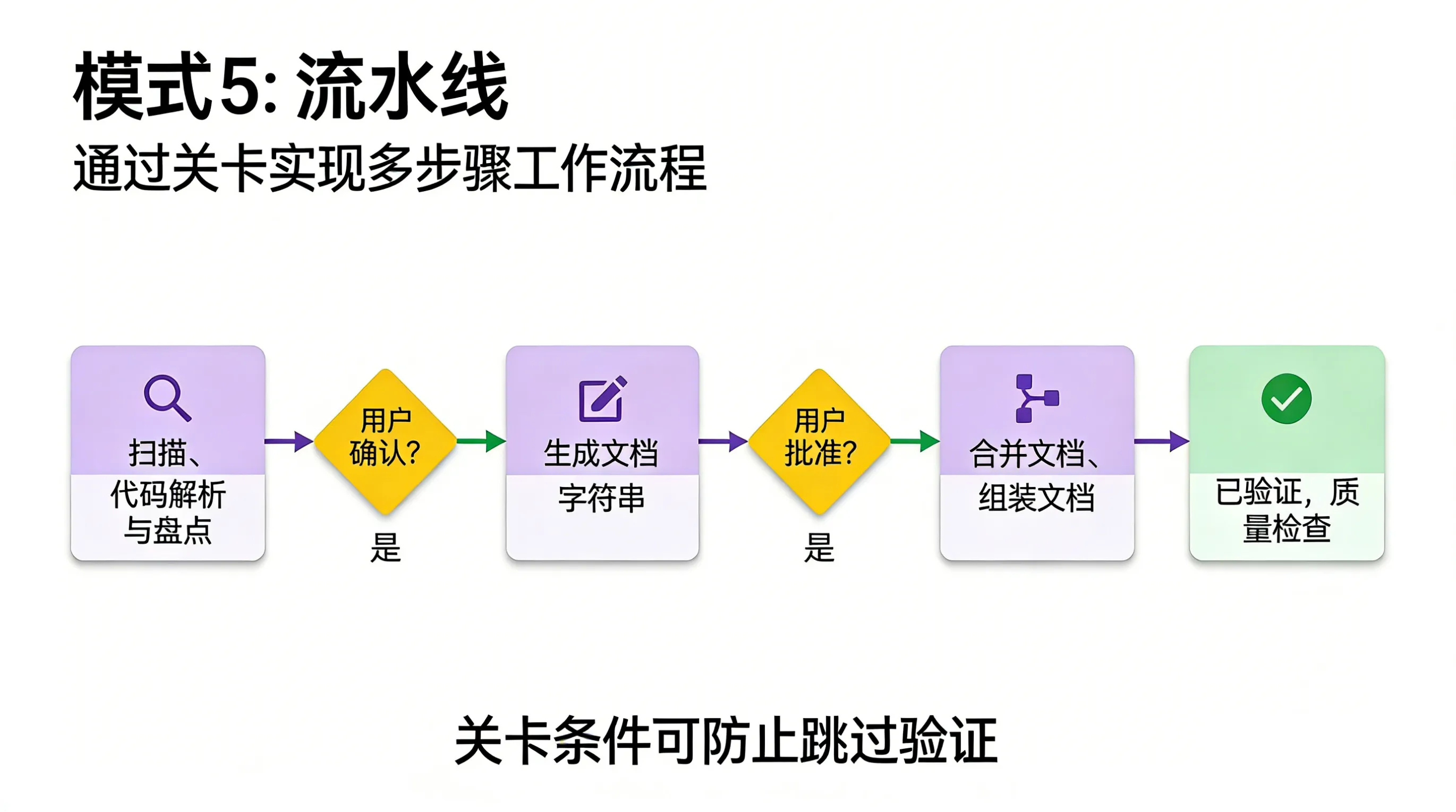
模式5:Pipeline——长任务别急着一次做完
我踩过的坑
最惨的一次,我写了一个翻译技能,一键启动翻译整个目录。结果跑到一半报错了——有的文件格式不对,有的内 容太长超token了。
更惨的是,我看不到到底是哪一步出错,只能从头再来。
那时候我就想:能不能分步做,每步都确认一下?
理论说的是什么
Pipeline 模式的核心是:多步骤任务要分阶段执行,每个阶段都要有检查点。
关键点:
- 显式检查点——每步结束后等待确认
- 按需加载——各步骤独立加载资源
- 不可跳过——防止用户图快跳过关键步骤
我在beaver-skill里的实现
beaver-markdown-i18n 就是吃过亏之后重做的:
Step 1: 扫描文件 → 展示扫描结果 → ⚠️ 等待确认 ↓Step 2: 生成任务 → 展示任务列表 → ⚠️ 等待确认 ↓Step 3: 执行翻译 → 展示翻译结果 → ⚠️ 等待确认 ↓Step 4: 生成报告每个⚠️都是检查点,出错的时候我知道是哪一步出了问题。
对照理论,我当时的改进:
| 理论要素 | 我的实现 | 对应位置 |
|---|---|---|
| 显式检查点 | 3个⚠️确认点 | SKILL.md 各步骤末尾 |
| 按需加载 | 各步独立加载references/ | references/ 文件 |
| 不可跳过 | Do NOT proceed until confirmed | SKILL.md |
回头看可以做得更好的地方
| 当前的做法 | 可以改进的地方 |
|---|---|
| 每步都要手动确认 | 可以加个”全自动模式”,但默认还是手动 |
| 出错后要重跑整步 | 可以支持从失败的chunk恢复 |
| 没有进度预估 | 可以在Step 1就显示预估时间和费用 |
模式组合——真实项目从来不是单一模式
我的发现
写 beaver-skill 这段时间,我发现一个有意思的事:没有哪个技能只用单一模式。
| 技能 | 主模式 | 辅助模式 | 为什么这么组合? |
|---|---|---|---|
| beaver-image-gen | Tool Wrapper | Pipeline | 多平台 + 偏好设置流程 |
| beaver-xhs-images | Generator | Inversion + Pipeline | 大纲生成 + 两次确认 + 4步流程 |
| beaver-cover-image | Generator | - | 单纯的填空生成 |
| beaver-release-skills | Pipeline | - | 发布工作流,强调流程控制 |
我的理解
Generator + Inversion = 先生成选项,再让用户确认 ↓ 用Pipeline封装 = 整个流程受检查点控制beaver-xhs-images 是最好的例子:
- Generator层:根据内容生成小红书图片大纲
- Inversion层:两次用户确认
- Pipeline层:4步流程,每步都要确认
给我自己的启发:设计技能的时候,别想”用什么模式”,而要想”需要解决什么问题”,然后自然就知道该组 合哪些模式了。
决策指南——遇到问题该用哪个模式?
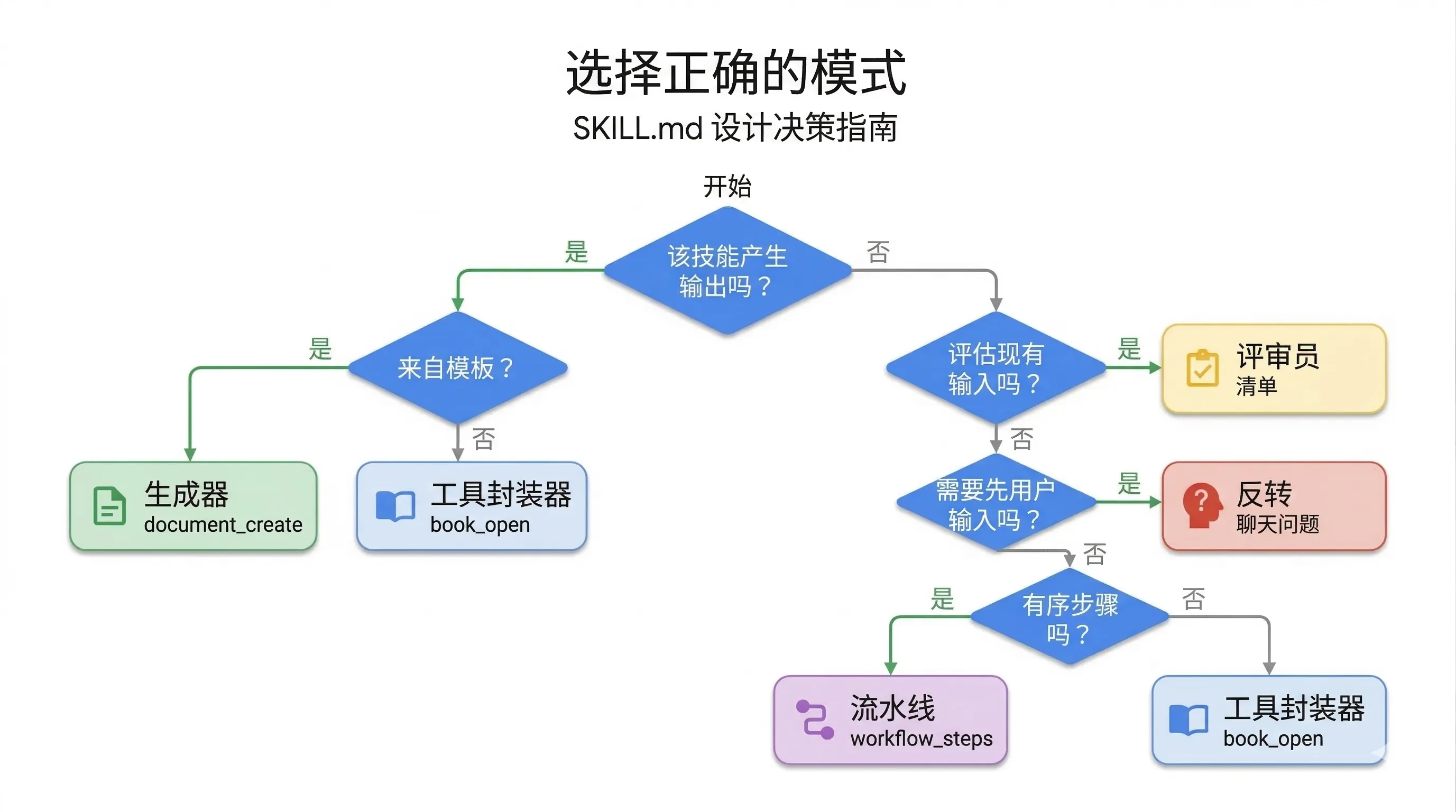
理论给了一个决策树,但我觉得还是对照表更实用。这是我整理的速查版:
| 我遇到的问题 | 该用什么模式 | beaver-skill有现成的吗? |
|---|---|---|
| 需要支持多个平台/API | Tool Wrapper | ✅ beaver-image-gen |
| 输出格式总是不稳定 | Generator | ✅ beaver-cover-image |
| 老是猜错用户需求 | Inversion | ✅ beaver-xhs-images |
| 多步骤任务容易出错 | Pipeline | ✅ beaver-markdown-i18n |
| 需要自动化审查代码 | Reviewer | 🚧 TODO列表上 |
我的使用流程:
- 先问自己”核心问题是什么?”
- 对着表找对应模式
- 看看 beaver-skill 里有没有类似的实现
- 复制结构,改内容
写在最后——我们都是在摸索中前进
看完这五种模式,对照自己写的代码,我有几个很深的感受:
1. 我当时的直觉方向没错
有些东西我凭直觉觉得”应该这样做”,比如把文档分开、分步执行、多问用户。看了理论才知道,原来这些就是”设计模式”。
这给了我信心——既然方向是对的,那就继续走下去。
2. 理论让我看清了可以改进的地方
比如平台检测的fallback机制、风格偏好的持久化、翻译任务的断点恢复……这些想法之前只是模糊的直觉,现在 有了清晰的方向。
下一步迭代,我知道该优化什么了。
3. 我们都是在AI新时代里一起探索
Agent开发还是个很新的领域,没有那么多”标准答案”。我们都是:
- 在黑暗中摸索方向
- 在实践中积累经验
- 在交流中互相启发
如果你也在做类似的事情,希望这篇文能帮你少走点弯路。我们一起在这条路上前进。
参考资源
- 理论来源:Google Cloud Tech - 5 Agent Skill design patterns
- 我的项目:BeaversLab/beaver-skill
- 技能参考:jimliu/baoyu-skills
如果你也在Agent开发的路上摸索,有什么心得或者踩过什么坑,欢迎一起交流。我们都是在AI新时代里探索的 同行者。
发布于: 2026年3月19日 · 修改于: 2026年3月19日

